In 2017, when BitMEX started using Kubernetes, we picked Weave Net as our overlay network for its obvious simplicity (150 lines of YAML, one DaemonSet, no CRD) and transparent encryption via IPSEC ESP. As our clusters grew bigger, with more and more tenants running real-time financial applications in production, the delusion has faded.
Fun, fun & more fun*
The first suspicious behavior we discovered early-on was the fact that network policies are in certain cases not enforceable as first reported in April 2018 and November 2018 and then somewhat documented in this table. Practically speaking, it means that within our Kubernetes clusters (with kube-proxy set to IPVS for scalability purposes, other parameters defaulted), Pods colocated on a node are able to communicate with each other via a ClusterIP Service regardless of any Network Policies in place.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
# Three Pods,two colocated, not necessarily in the same namespace clair-postgres-6dbcf456b8-2b8tj 172.16.220.32 ip-10-3-64-183.eu-west-1.compute.internal kayday-7765677f85-m6hvh 172.16.220.25 ip-10-3-64-183.eu-west-1.compute.internal kayday-558bddc868-cqm5c 172.16.40.7 ip-10-3-58-156.eu-west-1.compute.internal # One ClusterIP Service (backend endpoint is the clair-postgres-6dbcf456b8-2b8tj pod) clair-postgres ClusterIP 172.17.29.237->172.16.220.32 5432/TCP # Two Network Policies Name: deny-all Spec: PodSelector: {} Policy Types: Ingress --- Name: clair-postgres Spec: PodSelector: app=quay,role=clair-postgres Allowing ingress traffic: To Port: 5432/TCP From: PodSelector: app=quay Policy Types: Ingress # Now reaching the Network Policy'd Pod ## From a Pod running on another node, via its Pod IP or Cluster IP -- expectedly fails $ kubectl exec -it kayday-558bddc868-cqm5c /bin/sh -- -c -- -c 'echo "RIP" | nc -w3 172.16.220.32 5432 && echo "ok"' command terminated with exit code 1 $ kubectl exec -it kayday-558bddc868-cqm5c /bin/sh -- -c -- -c 'echo "RIP" | nc -w3 172.17.29.237 5432 && echo "ok"' command terminated with exit code 1 ## From a colocated Pod, via its Pod IP - expectedly fails $ kubectl exec -it kayday-7765677f85-m6hvh /bin/sh -- -c -- -c 'echo "RIP" | nc -w3 172.16.220.32 5432 && echo "ok"' command terminated with exit code 1 ## From a colocated Pod, via its ClusterIP - unexpectedly works $ kubectl exec -it kayday-7765677f85-m6hvh /bin/sh -- -c -- -c 'echo "RIP" | nc -w3 172.17.29.237 5432 && echo "ok"' ok |
While not ideal in the context of multi-tenant clusters, this particular issue can be worked around by enforcing scheduling-based isolation between workloads. Ironically, we later on up noticing the opposite: legitimate & previously allowed traffic towards new Pods (i.e. upon restarts and rolling updates) was being blocked. So we started investigating again. Looking at the code, we realized that weave-npc, the Network Policy controller, relies on three watch routines, and that there’s no logic in place to restart them upon failure or to propagate the failure up for a safe restart of the whole controller — meaning that the controller can stay up & running happily while satisfying only a fraction of its duties (or none at all, given the controller blocks waiting only for SIGINT/SIGTERM). Based on that finding, we looked through our logs, and soon enough found out that one of the routines indeed panic’d on every single node of our cluster at once from an evil assignment to entry in nil map.
Great, knowledge is power, isn’t it? We simply have to bounce all weave-npc processes & flag/fix the panic case to avoid any future occurrences. Oh, wait, nope! As we started rolling the Pods, our monitoring started complaining of transient connectivity issues… Back into the code, we quickly realized that upon restart, each weave-npc binary resets the entirety of the network policies on the hosts by flushing all IPtables & IPSets, and starts from scratch (as opposed to simply reconciling missed events). Such reset & re-installment takes well over 10 seconds on our clusters, in between which time traffic to our running Pods is then filtered (Deny All by default) — therefore technically creating staggered temporary network outages across the entire cluster.
That’s bad enough, so we started talking with Weaveworks about simply paying them for a fix — our bandwidth is limited, and building a relationship with the vendor can only be beneficial long-term. But those negotiations stalled as Weaveworks strictly insisted on only being able to do so if we were to sign a 12-months support contract.
At this point, my worst nightmare became having Weave Net issues in production. So it obviously happened, just a month later — weave-npc crashed & stayed in a crash loop across the board in one of our clusters, therefore creating a severe & widespread network outage (luckily short as we were able to quickly identify the problem). The source of the issue? As reported in June 2017, Weave does not support named ports in Network Policies as per the upstream Kubernetes API specification, and crashes instantly when a tenant runs an innocuous kubectl apply -f.
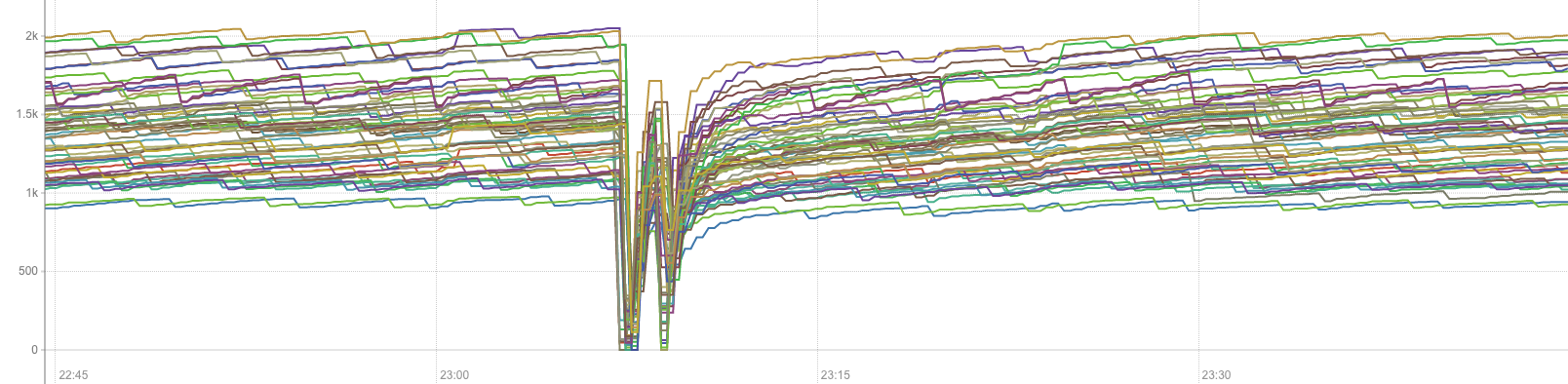
You’d think at this point we’ve have given up and replaced our CNI, but it seems that we tend to really like pain here, so I have one last short story to tell. Last month, our AWS VPC showed some signs of instability, causing short (one to two minutes) network unavailabilities on specific nodes, one at a time, over a period couple of two weeks. When a single AWS EC2 instance got a short network disconnection, we got the happy surprise to witness application & services, running on completely separate nodes, timing out, and being unable to route packets. In the chart below, tracking the number of inter-nodes flows Weave maintains, you can clearly appreciate how the Weave network collapsed across the entire cluster following a single instance event. The issue has been known since early 2019. I painfully remember similar charts in our early days, and not clearly understanding whether that would be a reporting error or a real problem as our observability & logging capabilities were not as advanced.
CNI Live migration
As one of the major derivatives trading platform in the industry, every single one of our production changes must be designed in a way that is the least disruptive for our high-frequency traders and that supports quick rollbacks. Interestingly, most of what we could find online, when it comes to CNI migrations, suggest either winging it by replacing the CNI and restarting all nodes at once (??), or creating a new cluster & migrating over, which sounds like a bit of a too much of a headache for what that migration really is. Consider Statefulset-managed quorum-based systems like Kafka.. and why would we need to bother moving volumes, DNS records, etc. Networking in Kubernetes is really not that hard, time to put back my CoreOS hat.
Let’s consider running both Weave and Calico side-by-side in a cluster, and ensuring that the networks are interoperable. Calico actually wrote a guide and controller for migrating from Flannel VXLAN to Calico VXLAN in place, which immediately gives us some confidence, although we are to deploy Calico IP-in-IP.
The first thing that comes to mind is that we should avoid getting in trouble with IPAM or with any conflicting routing / packet rewriting rules — picking a different Pod CIDR (aka ClusterCIDR) for Calico works around any of those potential issues with ease. The amazing thing is that once Weave & Calico run in parallel on every node is that we suddenly get two fully configured and fully working overlay networks on our Kubernetes cluster.. and that we can now instruct the kubelet, on each node individually, to schedule pods onto one or the other network. This means that, assuming both networks can intercommunicate (spoiler ahead – they do), we can perform a controlled staggered migration from one network to the other by simply letting pods restart (e.g. on their next deployment!), and rollback the migration equally as easily. All we need to do, is change the order of the CNI configuration files, and the kubelet will automatically reload the configuration after a few seconds.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# base network default via 10.3.96.1 dev eth0 proto dhcp src 10.3.96.175 metric 1024 10.3.96.1 dev eth0 proto dhcp scope link src 10.3.96.175 metric 1024 10.3.96.0/20 dev eth0 proto kernel scope link src 10.3.96.175 # weave network 172.16.0.0/16 dev weave proto kernel scope link src 172.16.208.0 # calico network blackhole 172.18.127.192/26 proto bird 172.18.38.64/26 via 10.3.107.246 dev eth0 proto bird 172.18.127.193 dev cali13cd0c8031c scope link |
|
1 2 3 4 5 6 7 8 |
$ ipvsadm -Ln | grep -A4 "172.17.0.10" Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP 172.17.0.10:9153 rr -> 172.16.50.9:9153 Masq 1 55 2 -> 172.16.12.12:9153 Masq 1 41 2 -> 172.18.30.13:9153 Masq 1 33 1 -> 172.18.248.1:9153 Masq 1 59 3 |
Kubernetes did a great job at decoupling itself from network plugins & configuration, yet the kube-controller-manager and kube-proxy expects the operators to provide a ClusterCIDR parameter. When it comes to the kube-controller-manager, it has a basic IPAM system called “host-local IPAM” that subdivides the provided ClusterCIDR and assigns a Node.Spec.PodCIDR to each node in the cluster, that the nodes’ CNI plugin can then consider for assigning Pod IPs in a simple and safe manner by inspecting the state locally — Calico supports multiple IP Pools, and therefore has a much more sophisticated IPAM algorithm, disregarding that value altogether. The kube-proxy is obviously a bit more intertwined as it plays a crucial role in Kubernetes networks by masquerading traffic, operating the magic behind the notorious Service IPs (either via IPVS or iptables) and setting up proper connection tracking. It’s still amazingly quite simple though, and also expect a ClusterCIDR argument, which it uses to determine which traffic must be masqueraded. While it does not support being passed multiple CIDRs, full functionality can be preserved by passing a ClusterCIDR that carefully overlaps both the Weave & Calico CIDRs. How easy.
The very last gotcha to this migration, Network Policies. Besides the policies hardcoded with cidrBlocks – which should be updated appropriately, network policies that use namespaceSelector & podSelector does not appear to behave properly with two overlay networks, most likely due to IP masking while jumping from one network to the other as Weave NPC relies on the Status.PodIP properly. Unless there are specific concerns doing so, Network Policies can be removed temporarily during the time of the migration.
All of that leaves us with a very simple no downtime migration procedure..
Pre-migration
- Deploy Calico
- Ensure CNI_CONF_NAME is set to “20-calico.conflist” to leave Weave as the default CNI
- Override CALICO_IPV4POOL_CIDR to a CIDR that’s different than the Weave CIDR & Service CIDR, but that can be grouped in a minimal overlapping superset CIDR with the Weave CIDR
- Set the ClusterCIDR parameter in kube-controller-manager and kube-proxy, to the CIDR that overlaps both the Calico and Weave CIDRs, and restart them
- Backup and delete all Network Policies (that’s where you can show off your bash foo to your coworkers)
Migration
For each node in the cluster that you wish to migrate over to using Calico by default, rename the CNI configuration files to change their ordering, and either wait for kubelet to pick up the change, or restart kubelet for a clean cut. Enjoy the sight of newly scheduled Pods coming up onto the Calico network (use
kubectl get pods -o wide).
|
1 2 3 4 5 |
for n in $(kubectl get nodes | awk '{print $1}'); do echo "Switch to Calico on node $n ssh core@$n "mv /etc/cni/net.d/10-calico.conflist /etc/cni/net.d/05-calico.conflist; systemctl restart kubelet --no-block" sleep 300 done |
Post-migration (After ensuring no pod use Weave)
- Remove Weave’s conflist file from every node
- Remove all the remaining Weave manifests / resources
- Restore all the Network Policies
- Set the ClusterCIDR parameter in kube-controller-manager and kube-proxy, to the Calico CIDR, and restart them
Will our lives be any better long-term with Calico? While we’ve been running Calico for a while in our production environments — it remains hard to say, as the saying goes, the green is always greener on the other side of the fence — but at least we are able to enjoy COVID19 peacefully knowing we’ll be able to update our network controller without disrupting our networks and the applications running on top of them.